نویسندگان فصلنامه فناوریهای مالی در نگارش مقالات خود از جدیدترین منابع داخلی و خارجی بهره میبرند. در این بخش، این مقالات و نویسندگان آنها بههمراه تاریخچه فعالیتشان معرفی شدهاند.
مقاله «مدلسازی فراگیری مالی و اثرات آستانهای آن بر رشد اقتصادی کشورهای عضو اوپک» که در سال 1399 در دوره 10، شماره 32 فصلنامه اقتصاد کاربردی منتشر شده به بررسی آثار فراگیری مالی بر رشد اقتصادی کشورهای عضو اوپک میپردازد.
کتاب «The Process of Economic Development» نوشته جیمز سایفر و چاپ انتشارات روتلج به پیچیدگیهای توسعه اقتصادی میپردازد. این کتاب نگاهی نقادانه به نظریهها، روالها و چالشهای مربوط به تحول اقتصادهای مختلف از وضعیت کمتر توسعهیافته به وضعیت پیشرفتهتر دارد.
مقاله «The logic of economic development: a definition and model for investment» که در سال 2016 در مجله «Environment and Planning C: Government and Policy» منتشر شده به چالش تعریف و اندازهگیری توسعه اقتصادی میپردازد.
مقاله «Digital financial inclusion: evidence from Ukraine» که در شماره سوم دوره شانزدهم مجله «Investment Management and Financial Innovations» منتشر شده اثر دیجیتالسازی بر فراگیری مالی در اوکراین را بررسی میکند. نویسندگان این مقاله میخواهند میزان فراگیری مالی را در این کشور ارزیابی کنند. هدف آنها درواقع شناخت موانع اصلی دسترسی به خدمات مالی است. اینکه ببینند اتصال جمعیت بزرگسال این کشور به خدمات مالی رسمی از طریق کانالهای دیجیتال نوآورانه چقدر امکانپذیر است.
مقاله «What Is Fraud Detection? Definition, Types, Applications, and Best Practices» به تعریف و معرفی انواع، کاربردها و شیوههای برتر تشخیص تقلب میپردازد.
مقاله «Unsupervised profiling methods for fraud detection» به تشخیص تقلب رفتاری از طریق تحلیل دادههای طولی میپردازد، درباره دو روش تشخیص تقلب بدون نظارت در دادههای اعتباری بحث میکند و آنها را در مجموعه دادههای واقعی بهکار میبندد.
چندین دهه است که سازمانهای مالی برای تشخیص تقلب به سیستمهای نظارتی مبتنیبر قواعد اتکا میکنند. اما این سیستمها اغلب خیلی ساختاریافته و انعطافناپذیرند و هر تلاشی برای اصلاح آنها ممکن است به فروپاشی کل پایگاه کد منجر شود.
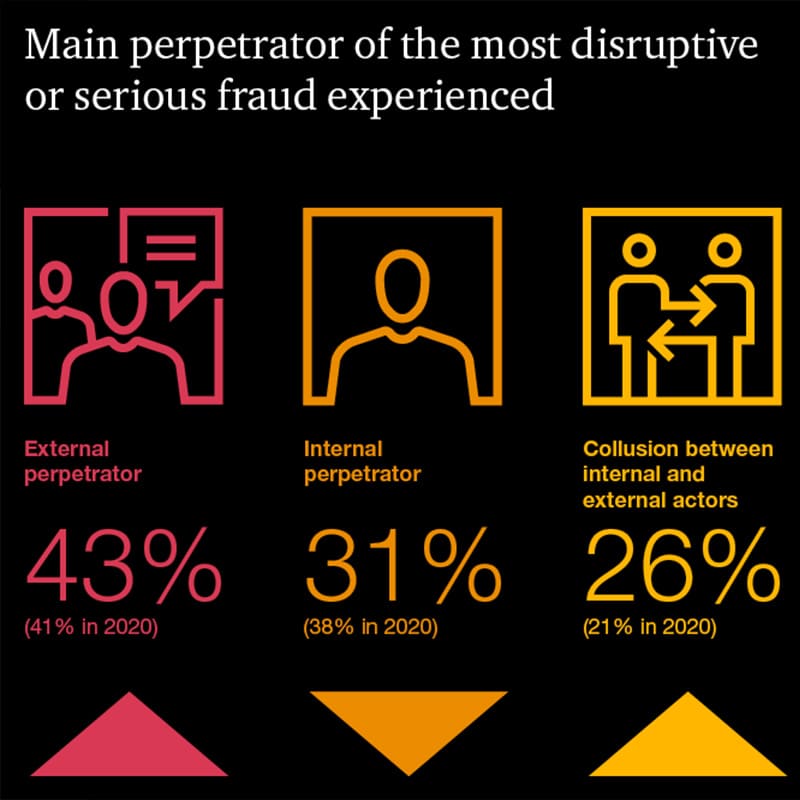
مقاله «PwC’s Global Economic Crime and Fraud Survey 2022» نگاهی جامع به چشمانداز کنونی جرم و تقلب اقتصادی دارد و ماهیت درحال تغییر تهدیدها و تمهیدات سازمانها برای مقابله با آنها را به تصویر میکشد.
مقاله «Outlier Detection Using Replicator Neural Networks» که در سپتامبر 2002 به همایش بینالمللی انبارداری داده و کشف دانش (International Conference on Data Warehousing and Knowledge Discovery) ارائه شده به چالش شناسایی دادههای پرت در پایگاههای داده بزرگ چند متغیره میپردازد. تشخیص دادههای پرت در استخراج داده برای کارهایی مثل پاکسازی دادهها و تشخیص تقلب حیاتی است.
مقاله «Machine Learning Models vs. Rule Based Systems in fraud prevention» که 14 مارس 2020 در وبسایت Nethone منتشر شده به مقایسه مدلهای یادگیری ماشین و سیستمهای مبتنیبر قاعده در پیشگیری از تقلب میپردازد، تفاوتهای این دو رویکرد را بررسی میکند و نشان میدهد که هر کدام از این رویکردها برای چه موارد استفادهای مناسبترند.